首頁 / 自我成長 / 為什麼有些技能你學得飛快,有些卻怎麼練都卡?
為什麼有些技能你學得飛快,有些卻怎麼練都卡?

- 同樣花力氣,有些技能學得飛快、有些怎麼練都卡,差別在環境:友善環境反饋快、準、規則穩,能快速迭代;險惡環境多人、反饋延遲、有噪音、規則會變,切斷了這條迭代線。而 AI 能把一部分險惡環境壓縮成友善環境,讓你先動再懂。
我有個怪癖,就是如果我沒有真的「搞懂」那個領域,那我通常就是擺爛不做。
搞懂是什麼意思?
我自己對搞懂的定義是,不是寫一篇文章就叫搞懂,是要把那領域能從 0 到 1 串通,解釋清楚,確定方方面面都是有效的,才叫搞懂。
所以我通常不是先做,再相信,而是反應弧很長的,花很久時間釐清關係,相信了,才開始做,這也是我行動力低落的原因。
從正面角度,你可以說我謹慎,不打無把握的仗。但負面角度,就是什麼都不做。
為什麼「想透了再行動」是條死路?
但我後來發現,這個毛病不全是我的問題 —— 很多時候,是環境問題。
我以前有提到說,我們的行為,牽扯到以往所有的經歷、反饋,它實際上是肉長的,是物理上的神經元連結。改變,就像地表上那株植物,但它下方其實有一整片死死扎進土裡、盤根錯節的龐大根系 —— 那是一套由信念、恐懼、舊有習慣與未知技能交織而成的地下網絡。
所以要靠想透,去行動,是一條漫長且不切實際的道路。
因為你的神經元連結已經被訓練好了,它有既定的路,每一次觸發情境都會往連結過多次,跑得很順的「預設道路」走。不管你腦中多麼清楚這件事才是正確的,但只要你沒開始做,那你的全身本能,舊有習慣,都會跳出來跟你對抗 —— 告訴你這是危險的,最終呈現的,就是活在習慣中,什麼都不會改變。
就像安德魯.胡伯曼(Andrew Huberman)博士說的:「若我們想先改變想法來達成改變,那絕對是愚蠢的做法。」
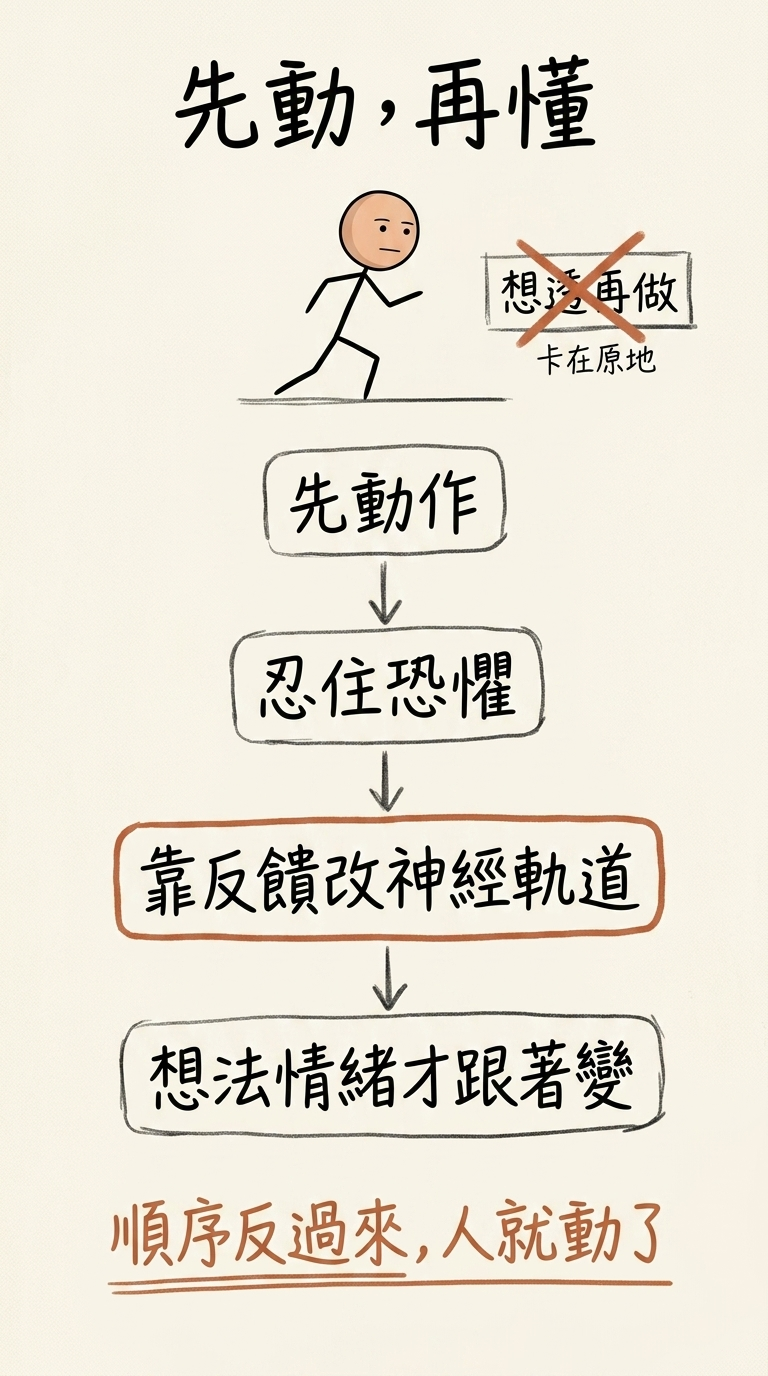
正確的做法,是要先從「行為」著手 —— 先動作 → 忍住第一次、第二次的恐懼 → 靠反饋的經歷,改變腦內預設的神經元連結軌道 → 知道說原來這樣做是沒危險的,是可行的 → 想法、情緒跟感知才會跟著改變。
為什麼同樣努力,有些技能學超快、有些怎麼練都卡?
行為改變,靠的是反饋。
你做一個動作,環境給你回應,你才知道這條路對不對。
問題是,反饋好不好拿,完全看你在什麼環境裡學。這就是為什麼同樣花力氣,有些技能我學得飛快,有些卻怎麼練都卡。
我發現,我學某一些技能時有巨大的優勢,像是有天賦一樣學的特別快。像是寫作、滑雪、Vibe Coding......,我總結他們之間有什麼規律時,發現高度重合:
- 單人遊戲
- 反饋快
- 反饋準
- 規則穩定
像是滑雪,比如說我學 S Turn,腦中剛想把身體重心往前壓時,5 秒後就會給我答案了,要馬是順利帥一波,要馬就是跌成狗吃屎,爬起來,身體微調後再試一次。就是一個行動的反饋太短太準確了,能馬上重來,一直迭代。
又比如,我寫作,寫完一段,唸過一遍,就馬上知道哪裡有語病,能馬上改。Vibe Coding 也是同樣道理,我腦中的想法交付後,等個幾分鐘 AI 就會給我結果,然後我又能再做修正。
那心理學家 Robin Hogarth 稱之為「友善環境」(kind environment),特徵是:規則穩定,能快速反饋。友善環境技能還包含了:樂器、唱歌、攝影、重訓、攀岩、烘焙、繪畫、書法......
什麼是「險惡環境」?為什麼這種技能特別難練?
但同時,我也發現,我對另一種類型的技能學得很辛苦,叫做「險惡環境」(wicked environment)。比如說業務,或是其他需要跟他人接觸互動、等待他人回應的。
特徵是:
- 多人遊戲(要至少兩人)
- 反饋有延遲
- 有噪音(被拒絕可能跟你無關)
- 規則會變
險惡環境不是簡單的因果關係。
比如說,同一句話對 A 有效,但卻會對 B 翻車,又或是他可能今天心情不好,所以不理你等等(反饋會被對方當天的情緒、狀態汙染)。這種技能我就不擅長,因為沒有既定公式,反饋也慢,甚至練習的樣本數可能少到讓你無法總結出什麼規律來 —— 像是我比較懶,不會主動跟人社交。
其它類似的「險惡環境」技能還有:業務、銷售成交、約會、談判(加薪、商業條件)、即興演講、臨場問答、辯論、辦公室博弈......
也就是說,友善技能之所以能進步飛快,是因為環境乾淨,你能把「我做了什麼」和「結果如何」直接連線。所以能夠「快速迭代→看反饋→修正」,而險惡環境由於它的長週期、慢反饋屬性,結果和行為常常對不起來,就切斷了這條快速迭代線。

甚至可能讓你得到錯誤教訓(把運氣當實力,或把實力當運氣)。
友善環境和險惡環境,訓練方式差在哪?
所以友善環境和險惡環境,訓練模式是完全不同的:
- 友善環境你能看結果,但險惡環境你只能看過程 —— 你無法控制單一結果,只能確保決策過程是對的。
- 友善環境單一樣本就能有反饋,但險惡環境要等樣本量 —— 一篇文章不爆,不說明什麼,寫了五十篇文章還是沒反應,這時才能找問題。
- 友善環境能自己驗收,但險惡環境要外接客觀指標 —— 把模糊成效拆成能量化,能檢驗的指標,不然會被噪音帶偏。
AI 怎麼把險惡環境變成友善環境?
以前,這兩種技能是涇渭分明的。
但 AI 正在將一部分險惡環境改造成友善環境。
因為 AI 能模擬體驗。
譬如你要面試,需要跟主管對談。以往我們只能看書,沒有辦法模擬對談。像考官會說什麼話,不知道,你該怎麼回覆,也不知道。而你如果沒有進入情境中,那就算看了再多概念,還是死知識,真正上戰場時,腦子還是會當機。
就像你可能遇到過這種情景:現場腦中有千百個思緒,卻一句話都說不出來,最後只能說出自己都不滿意的答案,等到回到家躺在床上時,才猛然醒悟,阿當時應該要那樣說才對。
這都是訓練不足的後遺症。
但現在你可以叫 AI 扮演考官,跟你來回對答,把所有的可能性都演練過一遍。或者你作為業務,可以把客戶會問的問題先準備出來,讓它扮演客戶對你找碴。又或者,你可以把當下真實案例直接輸入給它,問它怎麼辦,讓 AI 當軍師,提供回覆話術。
這就相當於是,將反饋迴路從「等對方回覆」壓縮成「立刻拆解」。

模擬,取代不了真人的不可預測。但險惡環境本來就是大數法則的遊戲 —— 讓 AI 陪你把所有的坑先踩一遍,真正需要真人的那一塊,就會愈削愈薄。
回到我開頭怪癖。以前我得先「搞懂」才敢動,結果就是卡在原地。
現在我多了一個選項:把那些搞不懂、得靠真人反饋的部分,丟給 AI 先演一百遍。
先動,再懂。
順序反過來,人就動了。

// 把這篇帶著走
友善環境與險惡環境,一鍵打包為 Notion 模板
重點濃縮 + 動手檢查表,留個 email,我直接寄一份可直接套用的版本給你。
P.S. 一週寄一封電子報,不喜歡退訂兩秒鐘 ✏️